OntoCast  ¶
¶
Agentic ontology-assisted framework for semantic triple extraction¶
![]()
![]()
![]()
![]()
![]()
Overview¶
OntoCast extracts semantic triples from documents using an agentic, ontology-driven pipeline. It co-evolves ontologies and facts graphs with parallel per-chunk processing, RDF 1.2 provenance, and optional vector-backed ontology retrieval.
Key Features¶
- Parallel map/reduce pipeline — concurrent per-unit ontology and facts loops
- Robust entity disambiguation — embedding + symbolic alignment across chunks
- RDF 1.2 provenance — quoted triples, provenance artifacts, optional
strip_provenance - GraphUpdate operations — token-efficient structured insert/delete triple patches instead of full graph regeneration
- JSON-LD wire format — optional
LLM_GRAPH_FORMAT=jsonldfor LLM payloads - Ontology context modes — catalog selection, vector retrieval (Qdrant or LanceDB), or fixed ontology
- Triple store integration — Fuseki (production) or in-memory pyoxigraph (default)
- Vector store integration — optional Qdrant (server) or LanceDB (embedded) for ontology patch retrieval
- Tenancy — partition datasets/collections by tenant and project
- REST API — document processing, ontology catalog management, graph matching
- Automatic LLM caching — disk cache with optional read-only mode, global in-flight limiting, and OpenAI Batch API pre-warming for benchmarks
- Structured documents — optional section tagging, section-aligned chunk labels, section filtering, and LLM summarization before extraction
Documentation¶
- Quick Start
- Workflow
- Core Concepts
- Configuration
- API Endpoints
- Tenancy
- Ontology Context
- Triple Stores
- LLM Caching
- API Reference
Installation¶
Optional PDF/DOCX conversion: pip install "ontocast[doc-processing]"
Quick Start¶
cp .env.example .env
# Edit LLM_API_KEY and paths
ontocast --env-path .env
curl -X POST http://localhost:8999/process -F "file=@document.pdf"
See Quick Start Guide for full configuration.
REST API (Summary)¶
| Method | Path | Purpose |
|---|---|---|
GET |
/health |
Health check |
GET |
/info |
Service metadata |
POST |
/process |
Full document pipeline |
POST |
/process_unit |
Single content unit |
POST |
/flush |
Clear triple store data |
POST |
/ontologies |
Upload catalog ontology |
PUT/DELETE |
/ontologies/{iri} |
Replace or delete ontology |
POST |
/match/entities |
Global entity alignment |
POST |
/match/derive-matches |
Pairwise entity matching |
POST |
/match/evaluate |
Triple/entity metrics |
Details: API Endpoints.
Workflow¶
Document-level pipeline (regenerated via uv run plot-graph):
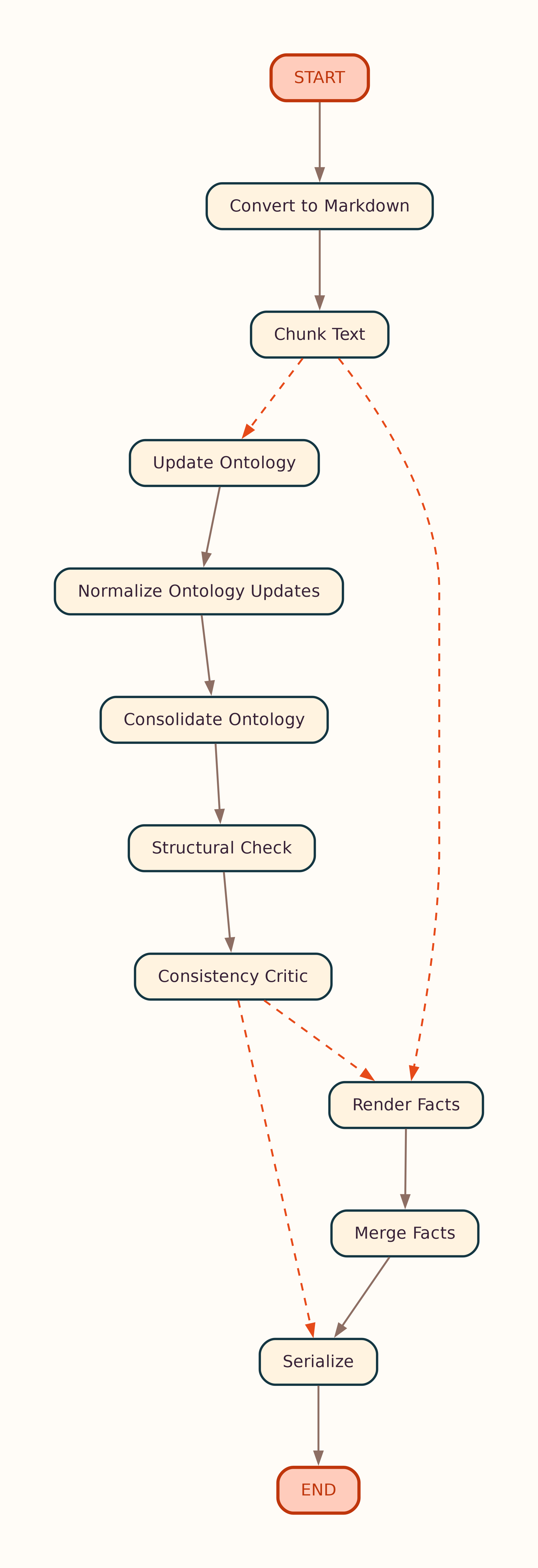
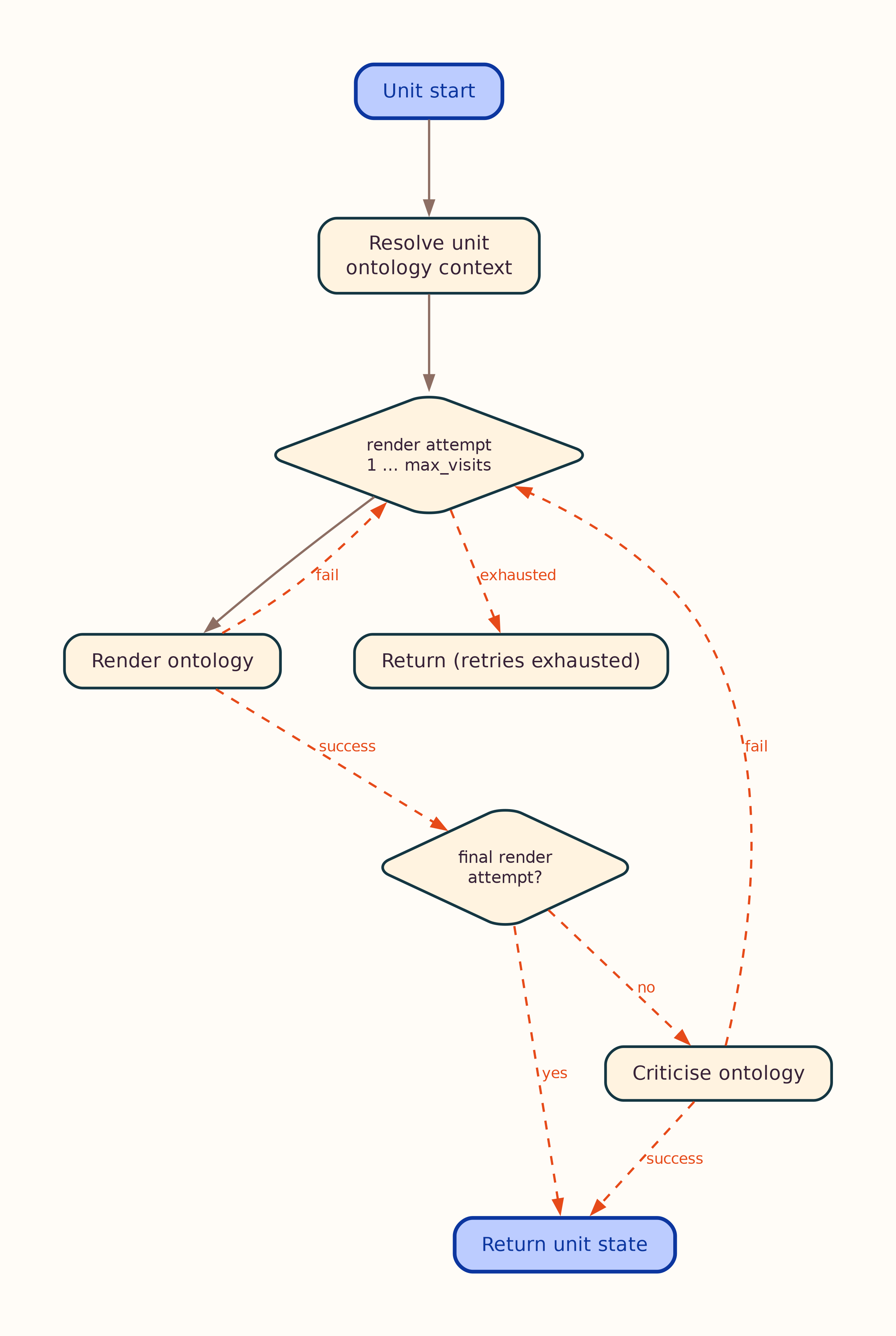
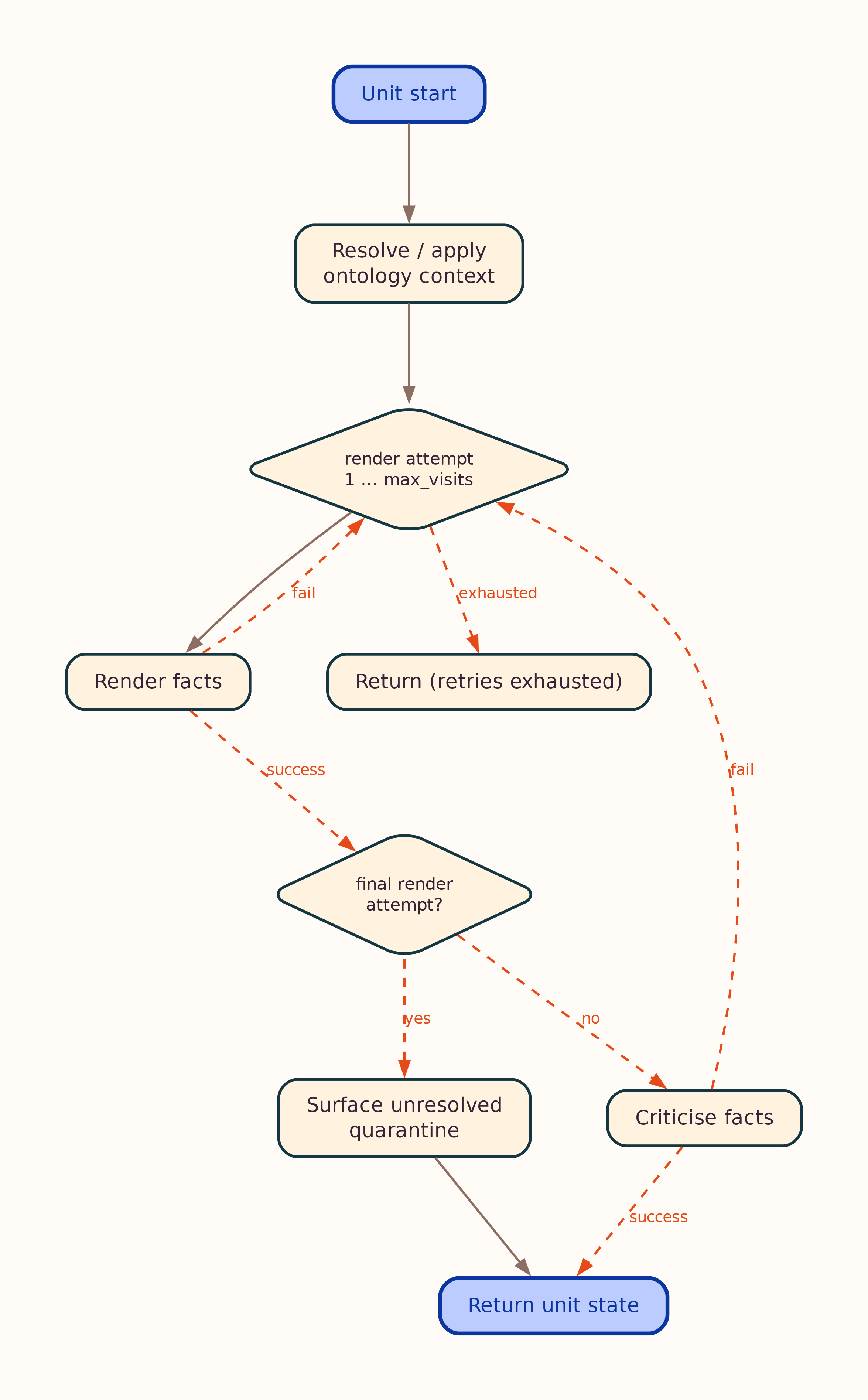
Landscape variant: graph.lr.png. Per-unit loops: ontology_loop.png, facts_loop.png — details in Workflow.
{kind=link}
{kind=link}
{kind=link}
- Convert → chunk prepare (segment, tag, filter, size) → optional summarize chunks
- Parallel ontology render per unit → normalize → optional consolidate → validate
- Parallel facts render per unit → merge with disambiguation
- Serialize to triple store; return Turtle in API response
Project Structure¶
ontocast/
├── agent/ # Render, critic, normalize, serialize agents
├── api/ # FastAPI routers (ontologies, schemas, tenancy)
├── cli/ # Server and utility CLIs
├── onto/ # Ontology, RDFGraph, state models
├── prompt/ # LLM prompt templates
├── stategraph/ # LangGraph workflow
├── tool/ # Triple stores, chunking, vector store, aggregation
├── config.py # Pydantic settings
└── toolbox.py # Tool dependency container
Contributing¶
See Contributing and CHANGELOG.